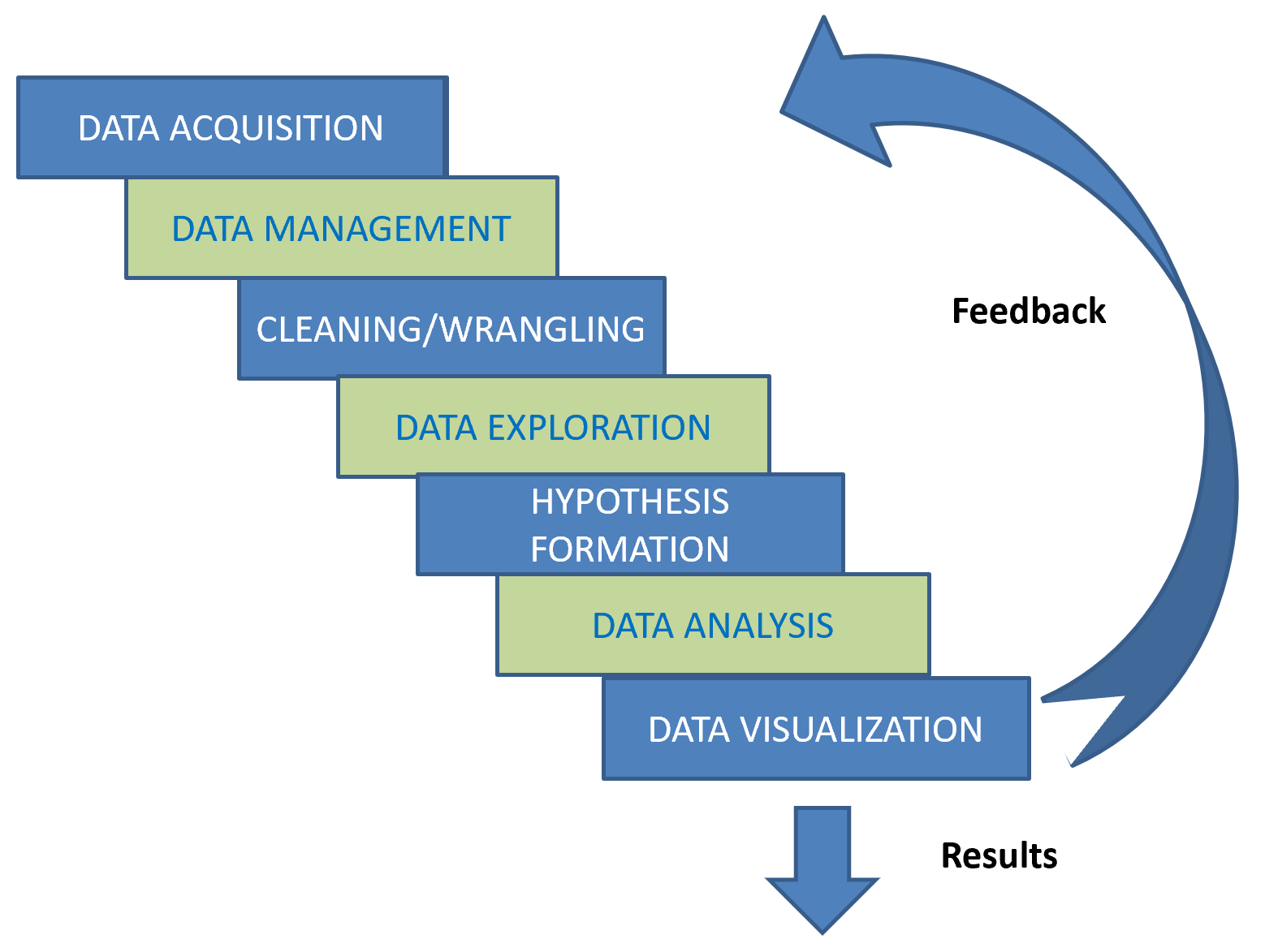
Data science starts with the data, and there are several steps to preparing data for exploration, hypothesis formation, analysis and visualization. First, data must be acquired. It may be available in your company’s databases, or you may need to find it in public or private data sources. Once obtained, the data is managed in a system, sometimes as simple as a spreadsheet but often a database system. It is evaluated for correctness, completeness and useability. Perhaps the source is authoritative and known to be correct. On the other hand, multiple data sources might be compared for consistency as a measure of likely correctness. Is data missing from the source? If it’s about universities, are all the universities represented? The data acquired might not be useable yet, because its in the wrong format or inconsistent. For example, the measurements in the data may be in different units than those needed, or the names used to describe people or objects may differ. Height might be in feet or inches or feet and inches. Rutgers might be Rutgers University or simply Rutgers. Data is placed in the needed format and made consistent in a process called cleaning or wrangling.
Once cleaned, your data can be analyzed. You might want to explore it a bit with queries or data visualizations to get a feel for what it says. Simple summarization or advanced hypothesis formation and testing can be done to gain insight into the data.
In the next posts, we will discuss obtaining and readying data for further exploration, analysis and visualization.