SRDR+ 5. Tips for Creating a Data Extraction Template
Now it is time to start building out the extraction template. You’ll find this tool under the Extraction Form Builder tab at the top.

Each tab has its own form. So, you will need to walk through each tab you have defined for your project. SRDR+ starts you out with a standard set of tabs, but you can customize these or add additional tabs. In the example below the Indexing Fields tab is a custom tab.
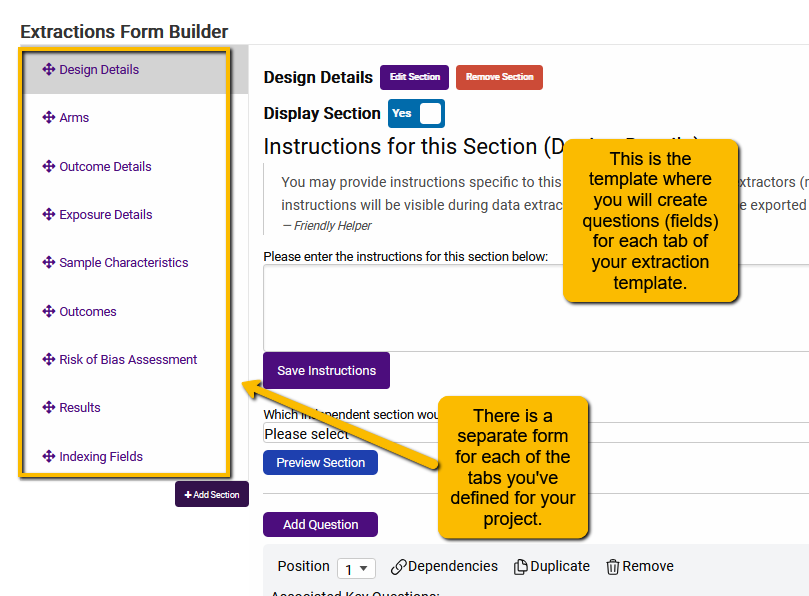
But before we talk about how to build out the different sections let’s talk first about some more general good practices for building an extraction template.
- 5.0.1 Structure Your Template Based on Your Analytic Framework
- 5.0.2 Organize Questions within Tabs
- 5.0.3 Goldilocks Principle for Data Collection
- 5.0.4 Use Dependencies to Help Your Extractors
- 5.0.5 Getting Started with the Extraction Template Builder
5.0.1 Structure Your Template Based on Your Analytic Framework
First, the types of information (data) that you’ll want to pull from the research articles should be guided by your PICO question and analytic framework. Take a look back at your PICO or your analytic framework and think carefully about the pieces of information you’ll need to answer your question. For instance, looking at this example analytic framework, we can already see a number of fields we will need to add to our extraction template:
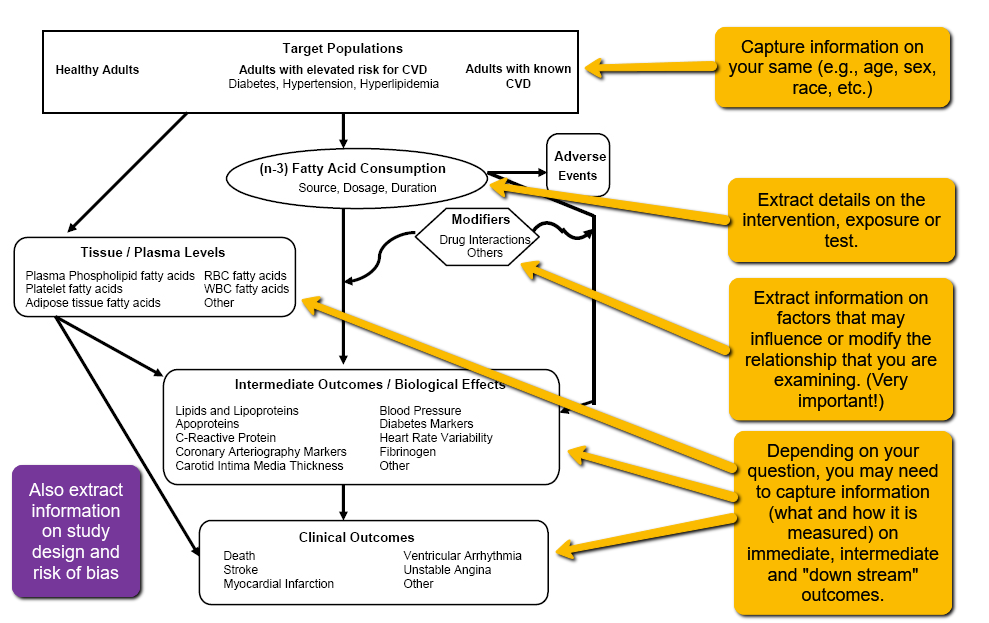
For additional ideas for field to extract for your project, see Chapter 5 of the Cochrane Handbook.
5.0.2 Organize Questions within Tabs
Second, know how to organize your questions within your template. Happily, SRDR+ makes this easier by organizing different types of information you’ll need into a series of tabs. Below is an example of a structured data entry form for the Design Details tab.
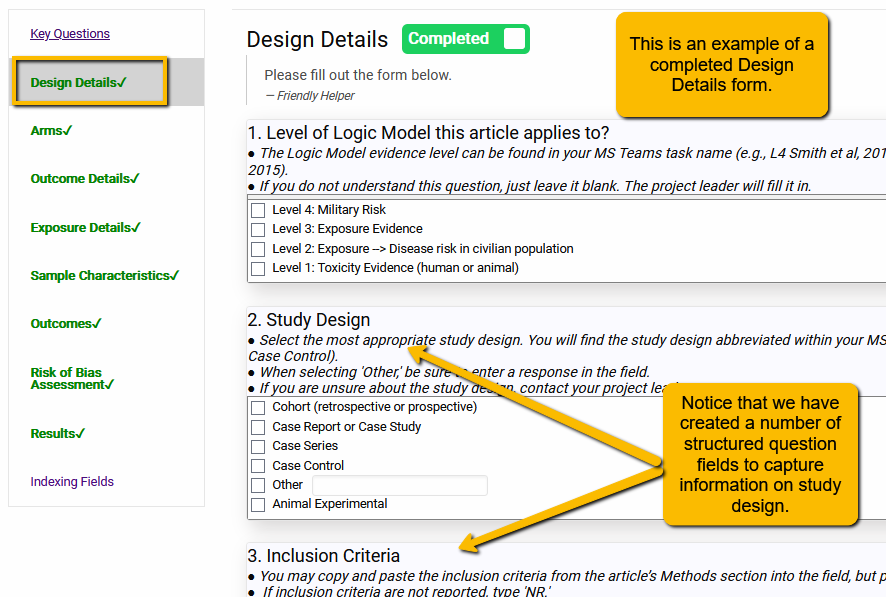
5.0.3 Goldilocks Principle for Data Collection
Third, remember that there is a balance between too little information and too much information. The principle of data extraction for systematic or scoping reviews is that you are extracting only the information you need and in a format that you can use. You don’t want to extract everything (otherwise, you could just work from the full text articles), but you want enough information to allow for your planned analyses.
- Too little information extracted will mean either a very limited analysis or may mean going back later to update your template to capture information you missed.
- Too much information, and you will find yourself wasting time extracting information that you will not need for your analysis.
For instance, it is very important to plan ahead of time for sub-analyses if you will be carrying out a meta-analysis. So, you’ll need to extract information about differences between the samples, interventions, measurement methods, etc. used in the different research articles. Taking these study characteristics into account can provide strong evidence for why interventions or exposures or tests work differently (i.e., have different outcomes) in different situations. But you have to plan ahead for capturing this information (without trying to extract every piece of information from a study).
5.0.4 Use Dependencies to Help Your Extractors
Fourth, you can use the Dependencies functionality to help guide the data extractors (and yourself) in knowing which questions to answer, and which they can safely ignore.
Let’s look at a simple example. You will notice below that there are two questions that I’ve set up to capture detail on different types of interventions. The first question lists different types of physical therapy interventions. Subsequent questions capture more detail on these general types of therapy. However, only the relevant later questions will highlight. Questions that are not relevant will be grayed out.
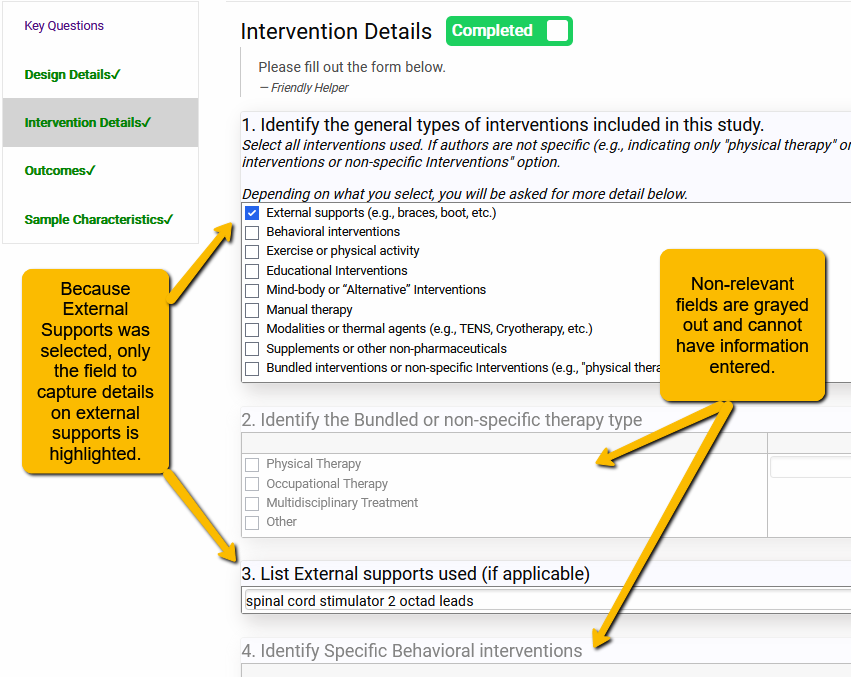
How do you set up a dependency between questions? You will find the tool to define dependencies in the Extraction Template builder. The Dependencies button is at the top for each question.

When you click on the Dependencies link, you’ll see:

Once you have set the appropriate dependencies, click the Save and Exit button at the top right of the dependency tool screen.
5.0.5 Getting Started with the Extraction Template Builder
When you first open the Extraction Form Builder, you will be taken to the page to structure the Design Details tab first. You will see the following:
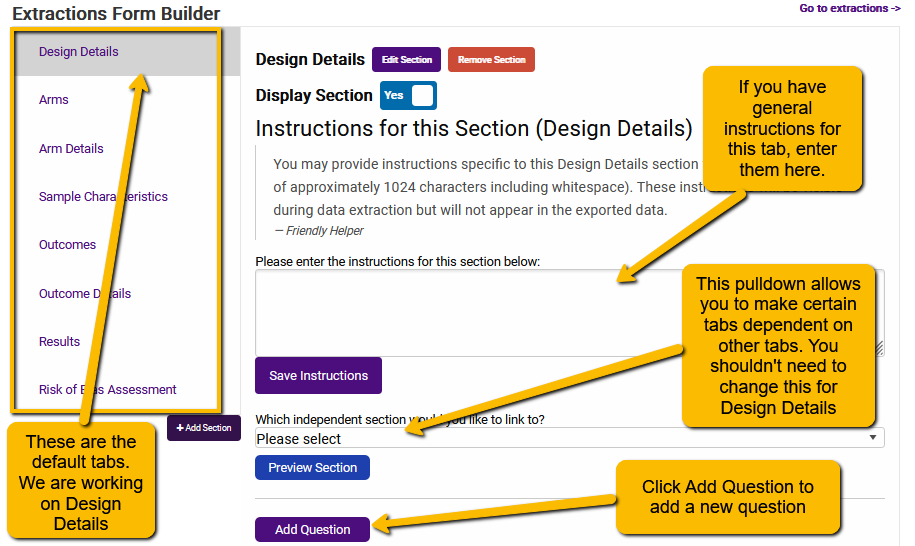
There are several components:
List of Available Tabs: On the left you will see a list of the default tabs defined by SRDR+.
Add Section Button: Below this list is a button: Add Section. While most projects will not require any additional tabs, you have the flexibility to add additional tabs.
Save Instructions: If you have general instructions for extractors for the particular tab, you can enter those instructions in this text box.
Tab Dependencies: There are two key tabs that structure other tabs: Arms and Outcomes. If you make Arm Details dependent on Arms, then each question in Arm Details will repeat for each arm defined in the Arms tab. Similarly, if the Outcome Details tab is dependent on the Outcomes tab, then each question on the Outcome Details tab will repeat for every outcome defined on the Outcomes tab. Finally, if you are going to carry out risk of bias for each outcome (rather than the article as a whole), you will want to make the Risk of Bias tab dependent on Outcomes.
Preview Section: You can use this button top preview the look of your questions.
Add Question: This button allows you to add a new question.
What’s Next?
The next series of pages will show you how to actually set up different types of questions in SRDR+.